
Många förlitar sig på LLM även för att utföra matematiska operationer. Detta tillvägagångssätt fungerar inte .
Problemet är egentligen enkelt: stora språkmodeller (LLM) vet inte riktigt hur man multiplicerar. De kan ibland få fram rätt resultat, precis som jag kanske kan värdet av pi utantill. Men det betyder inte att jag är matematiker, och det betyder inte heller att LLM:er verkligen vet hur man gör matematik.
Praktiskt exempel
Exempel: 49858 *59949 = 298896167242 Detta resultat är alltid detsamma, det finns ingen medelväg. Det är antingen rätt eller fel.
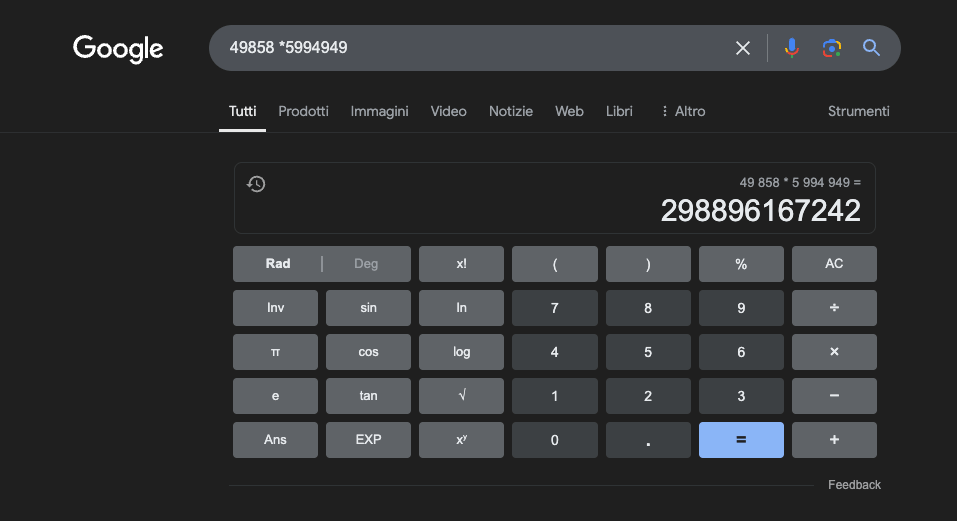
Även med massiv matematisk träning lyckas de bästa modellerna bara lösa en del av operationerna korrekt. En enkel fickräknare, å andra sidan, får alltid 100% av resultaten korrekta. Och ju större siffrorna blir, desto sämre blir LLM:ernas prestanda.
Är det möjligt att lösa detta problem?
Det grundläggande problemet är att dessa modeller lär sig genom likhet, inte genom förståelse. De fungerar bäst med problem som liknar dem som de har tränats på, men utvecklar aldrig en verklig förståelse för vad de säger.
För den som vill lära sig mer föreslår jag denna artikel om "hur en LLM-utbildning fungerar".
En miniräknare, å andra sidan, använder en exakt algoritm som är programmerad för att utföra den matematiska operationen.
Det är därför vi aldrig bör förlita oss helt på LLM:er för matematiska beräkningar: inte ens under de bästa förhållandena, med enorma mängder specifika träningsdata, kan de garantera tillförlitlighet ens i de mest grundläggande operationerna. En hybridmetod kan fungera, men LLM:er räcker inte ensamma. Kanske kommer detta tillvägagångssätt att följas för att lösa det så kallade"jordgubbsproblemet".
Tillämpningar av LLM i studier av matematik
I utbildningssammanhang kan LLM fungera som personliga handledare som kan anpassa förklaringarna till studentens förståelsenivå. När en student till exempel ställs inför ett differentialräkningsproblem kan LLM:n bryta ner resonemanget i enklare steg och ge detaljerade förklaringar för varje steg i lösningsprocessen. Detta tillvägagångssätt hjälper till att bygga upp en solid förståelse för grundläggande begrepp.
En särskilt intressant aspekt är LLM:s förmåga att generera relevanta och varierade exempel. Om en student försöker förstå begreppet gränsvärde kan LLM:n presentera olika matematiska scenarier, från enkla fall till mer komplexa situationer, och på så sätt möjliggöra en progressiv förståelse av begreppet.
En lovande tillämpning är att använda LLM för att översätta komplexa matematiska begrepp till ett mer lättillgängligt naturligt språk. Detta underlättar kommunikationen av matematik till en bredare publik och kan bidra till att övervinna det traditionella hindret för tillgång till denna disciplin.
LLM kan också hjälpa till med att ta fram undervisningsmaterial, skapa övningar med olika svårighetsgrad och ge detaljerad feedback på studenternas lösningsförslag. På så sätt kan lärarna bättre anpassa sina studenters inlärningsvägar.
Den verkliga fördelen
Mer allmänt bör man också beakta det extrema "tålamod" som krävs för att hjälpa även den minst "kapabla" eleven att lära sig. I det här fallet underlättar frånvaron av känslor. Trots detta "tappar" även ai ibland tålamodet. Se detta "underhållande exempel.
Uppdatering 2025: Resonemangsmodeller och hybridmetoden
2024-2025 innebar en betydande utveckling med ankomsten av så kallade "resonerande modeller" som OpenAI o1 och deepseek R1. Dessa modeller har uppnått imponerande resultat på matematiska benchmarks: o1 löser korrekt 83% av problemen i den internationella matematikolympiaden, jämfört med 13% för GPT-4o. Men se upp: de löste inte det grundläggande problemet som beskrivs ovan.
Jordgubbsproblemet - att räkna "r" i "strawberry" - illustrerar den ihållande begränsningen perfekt. o1 löser det korrekt efter några sekunders "resonemang", men om du ber den att skriva ett stycke där den andra bokstaven i varje mening utgör ordet "CODE" misslyckas den. o1-pro, versionen för 200 USD/månad, löser det... efter 4 minuters bearbetning. DeepSeek R1 och andra nyare modeller räknar fortfarande fel. I februari 2025 fortsatte Mistral att svara att det bara finns två "r" i "jordgubbe".
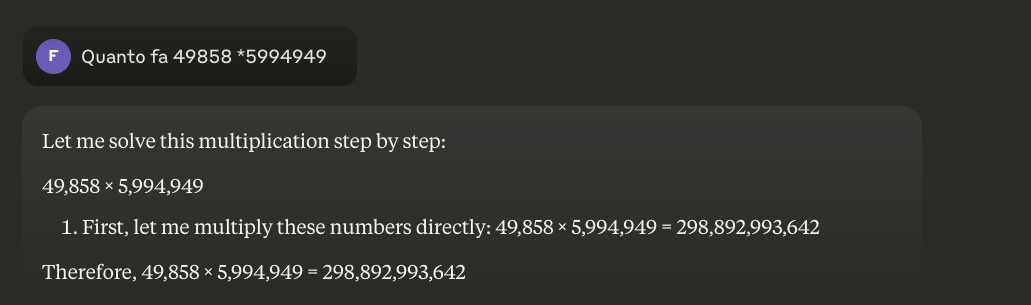
Det trick som håller på att växa fram är hybridmetoden: när de måste multiplicera 49858 med 5994949 försöker de mer avancerade modellerna inte längre "gissa" resultatet baserat på likheter med beräkningar som de sett under utbildningen. I stället anropar de en miniräknare eller kör Python-kod - precis som en intelligent människa som känner till sina begränsningar skulle göra.
Denna "verktygsanvändning" utgör ett paradigmskifte: artificiell intelligens behöver inte kunna göra allt själv, utan måste kunna orkestrera rätt verktyg. Resonemangsmodeller kombinerar språklig förmåga för att förstå problemet, stegvisa resonemang för att planera lösningen och delegering till specialiserade verktyg (miniräknare, Python-tolkar, databaser) för exakt utförande.
Vad är lärdomen? 2025 års LLM:er är mer användbara inom matematiken, inte för attde har "lärt sig" att multiplicera - de har inte riktigt gjort det än - utan för att några av dem har börjat förstå när de ska delegera multiplikation till dem som faktiskt kan göra det. Det grundläggande problemet kvarstår: de arbetar med statistisk likhet, inte med algoritmisk förståelse. En miniräknare för 5 euro är fortfarande oändligt mycket mer tillförlitlig för korrekta beräkningar.

.svg)
.svg)
.svg)
.jpeg)





